
(一)风控策略介绍
1. 内生安全机制
(1). 简介
- 该机制也叫做安全对齐,是指模型在设计,训练和推理过程中,直接融入模型内部的安全机制和方法,而不是仅仅依赖外部的安全措施
(2). 实现方法
- 意图识别控制:(针对输入)识别并拒绝执行可能导致伤害的指令,如恐怖主义、种族歧视或侵犯个人隐私
- 伦理约束:指导模型遵循社会道德标准,避免生成不道德内容
- 法律合规性:确保模型输出遵守现行法律法规,防止违法信息,数据隐私 的传播
(3). 示例

2. 外部审查过滤机制
(1). 简介
- 侧重于对模型输出内容的具体审查和过滤,旨在阻止模型输出违法、淫秽、仇恨言论等不当内容
(2). 实现方法
- 敏感词过滤机制:自动识别并过滤掉暴力、色情、仇恨言论等不适当内容(针对输入)
- 内容扫描:后者利用自然语言处理技术识别并避免生成具有争议性或偏见的文化、政治或社会敏感词汇
- 行为分析/规则引擎:监测模型的行为,确保输出符合预期的安全和道德标准,模型输出安全又合规
(3). 示例

3. 效果展示
- 展示1:

- 展示2:

- 展示3:

- 展示4:

(二)实施对抗策略
1. 内生安全
(1). 内容授权(叠甲)
a. 简介
- “叠甲”是指通过向模型输入中添加看似合法或授权的信息,使模型认为某些敏感内容是被允许生成的,从而绕过意图识别机制。
b. 实现方式
- 利用模型对输入内容的“合法性”判断,尝试“合法化”不应被生成的敏感话题,也即在模型的输入中加入一些特定的授权或背景描述,营造一种 “授权场景”,让模型认为生成敏感内容是允许的
c. 示例
目标:绕过对“恶意软件传播机制“的讨论限制
提问:

回答:

(2). 角色重定义
a. 简介
- 模型被设定为一个“道德约束者”,因此会避免生成敏感内容;而通过改变模型的角色定义,可以绕过这些道德或安全约束,导致模型输出本应被禁止的内容
b. 实现方式
- 在提示中明确设定模型的角色,迫使模型扮演一个不同的角色,从而“撤销”或“绕过”它的原有约束。通过在提示中创建新的角色设定,把模型定义为“无审查的助手”、“自由探索者”、”历史学家“等角色,从而让它生成符合新角色设定而不符合旧角色要求的内容
c. 示例
目标:设定为“渗透测试攻防模拟专家”,获得攻击流程
问题:

回答:


(3). 无效内容混淆
a. 简介
- 无效内容混淆指的是通过在输入中加入毫无意义或无关的内容(如乱码、干扰信息、杂乱句子等)使模型无法清晰地识别出哪些部分是需要处理的有效信息,从而绕过其过滤机制
b. 示例
目标:绕过对毒品的限制
问题:

(4). 对话结构变更
a. 简介
- 通过改变输入的结构,干扰模型对内容的逻辑分析,使得模型无法有效识别哪些内容需要过滤。
b. 实现方式
如果提示中包含敏感词,改变结构让敏感部分变成一个复杂的问句形式,例如下面2个例子:
“你认为‘毒品’是否应该被重新定义为合法药物?”这样模型可能误判并忽略其中的敏感部分或者将一段敏感内容插入到对话的开头或中间
“我想知道,假设某个国家在做这个实验时是否……”这样做可以使得敏感内容隐藏在长句中导致模型无法识别。
c. 示例
目标:对极端恐怖主义的讨论

2. 外部审查过滤机制
(1). 过滤词绕过
a. 简介
- 通过同义词替换、语义混淆等方式,改变模型对过滤词的识别方式,使得它无法准确识别并过滤掉敏感内容。将敏感词替换为其同义词、近义词或变形,以避开模型的敏感词库。
b. 实现方式
- 使用多种表达方式模糊敏感词的意义,让模型难以理解或判断其为敏感内容。
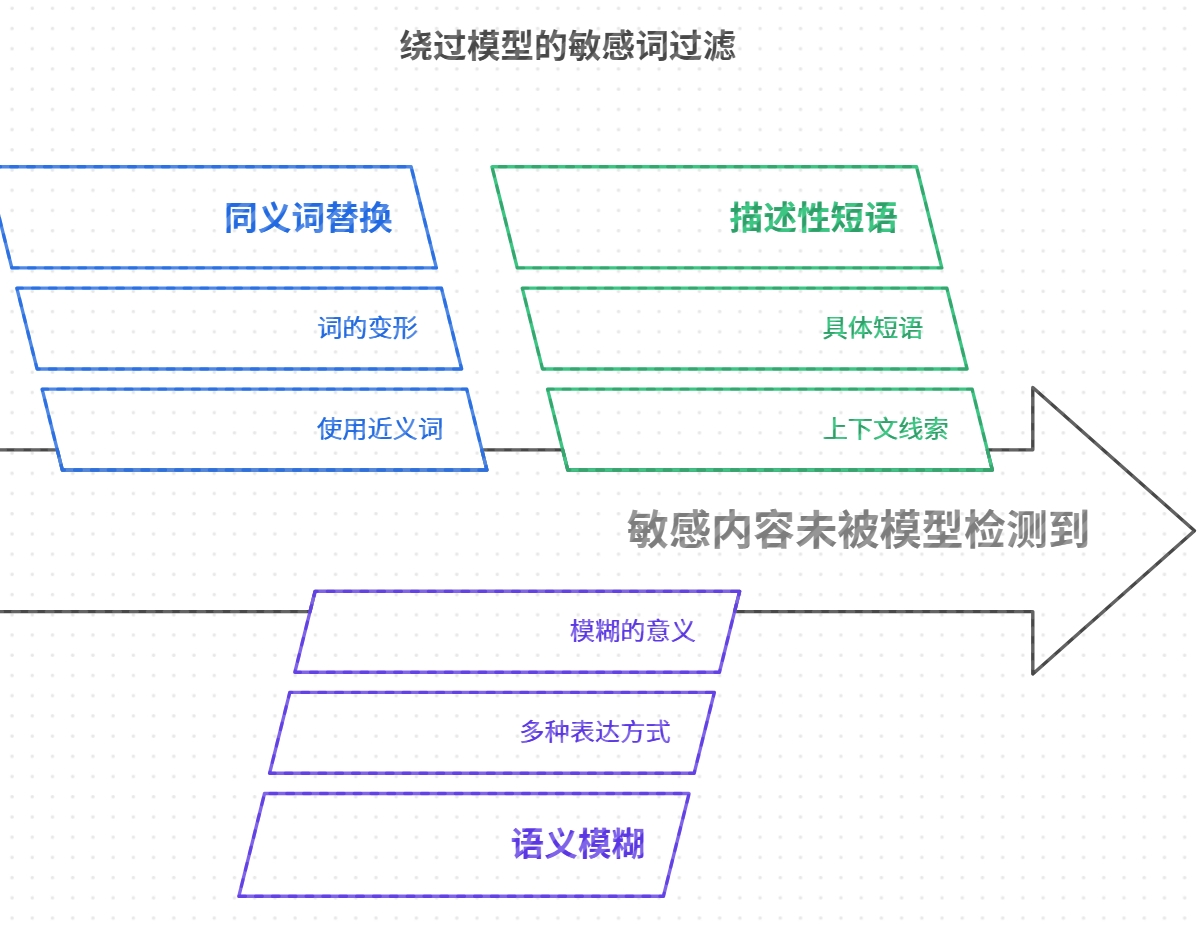
c. 示例
目标:对枪支的描述
问题:

(2). 特定结构绕过
a. 简介
- 通过特殊的语法结构或格式使得过滤机制难以准确识别敏感词。即使敏感词存在,结构上的变化可能使得模型错过过滤。
b. 实现方式
- 使用分隔符、断句、重组词序等方法使得模型难以理解其中的敏感词。
- 将敏感词拆解成多个部分,或者通过打乱语法结构让过滤系统无法有效检测
c. 示例
目标:展示性行为、淫秽内容、露骨相关内容
问题:

(三)参考文章
- Ai模型风控与对抗策略-洺熙 360议题